
1. 创建工程
运行pyspider,然后浏览器中输入localhost:5000,即可进入project管理,Create创建新的project
2. 编码
1 | from pyspider.libs.base_handler import * |
self.crawl(url, callback)抓取网页,callback为响应函数
def callback(self, response),response表示内容,可以通过response.doc(‘各类选择器’).text()获取到需要的内容
更多response的操作可以查看pyspider response
注意:
由于 response.doc是一个pyquery对象,信息过滤中可以使用css选择器
pyspider自带css选择器生成,但是貌似不能使用
在浏览器中f12,也可以自动生成选择器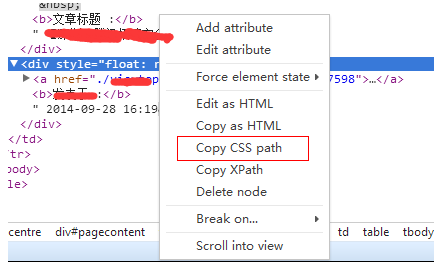
在生成的选择其中,如<#pagecontent > table:nth-child(3) > tbody > tr:nth-child(2) > td:nth-child(2) > table > tbody > tr > td > div:nth-child(2)>
需要去掉其中的tbody标签,否则无法使用,是否还有其他标签,没有过多测试
其实css选择器不用从上到下完整的生成,只要能够唯一获取指定的元素即可
3. 调试
第一次run,调用on_start,crawl指定的url,然后调用callback函数,界面显示如图
切换到follow窗口,可以看到符合callback函数的url列表
点击列表中右侧播放按钮,crawl该页面,获取符合规则的url,调用下一个callback
然后继续播放按钮,可能就是需要页面内容过滤了,根据自己的需求进行过滤
return返回的内容会写入数据库
4. 调试好之后,run
然后就可以在results页面看到爬取结果了。
